咱们今天聊的是一个互联网巨头的SRE(网站可靠性工程)团队是怎么搭建起来的,这个故事由国内最火的IT服务管理社区——ITIL先锋论坛来讲述。这里面可是满满的干货,他们从大公司的SRE规划、业务部门怎么执行、SRE的边界在哪里这三个角度,把这家公司的SRE建设经验掰开了揉碎了讲给你听。
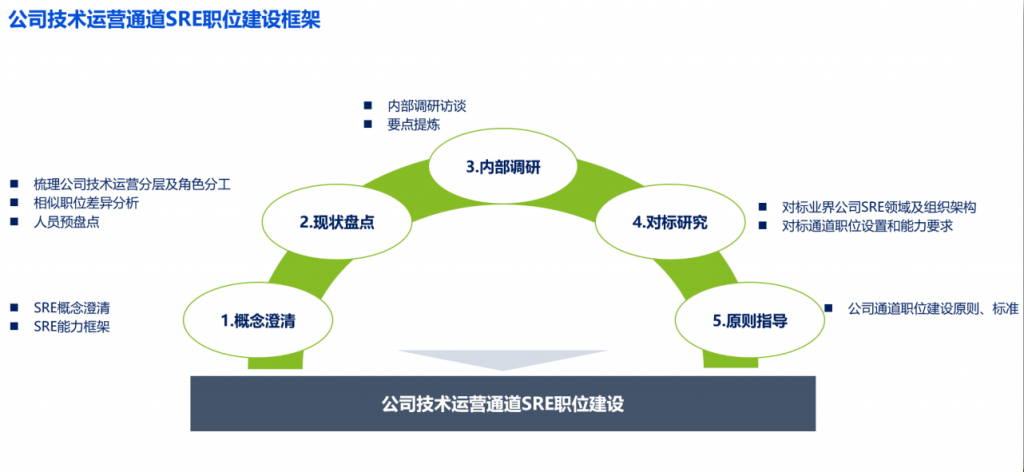
先说说大公司的SRE规划: Google的SRE模式,说白了就是用软件工程师来升级软件系统,让自动化来取代那些繁琐的人工操作。SRE团队里,大概有一半到六成是标准的软件工程师,剩下的四到五成是其他技术领域的高手。SRE团队最讨厌的就是重复和手工的活儿,他们擅长用软件快速开发出系统来取代那些手工操作。SRE团队和产品研发部门在学术和工作背景上挺像的,基本上就是用软件工程的招数来搞定以前系统管理团队手头上那些活。
再来看看业务部门怎么执行: SRE平台工程和SRE技术服务的概念,强调了工程化思维和参考理论资料的重要性。具体来说,有这么几个方面: - SRE平台工程:这包括了定制化桌面、开发者中心、开发框架、企业服务总线、API网关、单点登录、低代码平台等等。 - SRE技术服务:这个就更丰富了,有用户管理、配置平台、作业平台、容器管理平台、计算平台、AIOps平台、项目管理等等。 - 业务生命周期:从需求出发,结合理论资料和工程化思维,应对研发需求变化、云原生、游戏研发模式变化、DevOps工程、GitOps、CI/CD、微服务比例增加、全球多地协同研发、制作管线工程、业务全球化、多国多地区版本发布、微服务和容器化、自动化工程、ITIL的AI融合、长尾业务、可观测工程、稳定性、容量工程、自动评估和成本控制、可靠性工程、MTBF/MTTR、混沌工程、AIOps工程等等等等。
再说说SRE的边界在哪里: SRE的边界和前沿试错,强调了SRE在研发可用性建设中的重要性。具体措施包括: - SRE驱动的研发工业化改造:就是构建可用性提升的preBuild方案细节,从头到尾,从里到外,只费力不费钱,高控限用,谢绝行绝不的,要线升生产环境约除空性能婴质。 - SRE驱动的云原生改造:这个就更专业了,包括ClusterAutoscaler、Kubernetes、AWS、Meia fss、ClusterManager、LgsEtaM等资源池试点转型团队的阶段性进展。 - SRE在游戏中的指标设计与实践:CA扩展基础模型,研发运维关注的云原生业务的指标,包括ClusterAutoscaler、Kubemetes、AWS等等。
最后看看实施效果: 实施SRE组织建设的成效,包括: - 团队能力提升:500+团队成员,10+业务支撑转变为多工程并行,44+云原生改造业务,23%月优化运营成本,8+人均业务数,60+人均效能提升,400W可观测能力项,代码即运维能力,SLI/SLO。 - 管理模式创新:降低成本、复用人力资源,把固定业务运维模式变成跨业务运维模式;长尾业务平台化管理,实现多人互备,多人Oncall的模式;增效、业务支撑转变为多工程并行,提升支撑效率;工程化运作模式,强调工作长期价值和复用价值,提升多业务服务效率。 - 人才培养:建立SRE人才梯队培养模式,定义各专业职级与必修的工程场景对照;OnCall互备可以降低工作压力,跨游戏业务服务可以降低工作枯燥感。
这篇文章给互联网公司的SRE组织建设提供了宝贵的实践经验,展示了如何通过SRE平台工程和SRE技术服务,提升团队能力,创新管理模式,培养SRE人才,实现降本增效。报告强调了SRE在研发可用性建设中的重要性,以及在云原生改造中的关键作用,为其他企业提供了可借鉴的实践路径。
| 
 转播
转播 分享
分享 淘帖
淘帖 ()
()